最近、友人が物件ファンという物件紹介サイトで記事を書いているらしい。その友人の書いた記事を、機械学習で探し出す、という遊びを年末にやったので、それの記録。
こちらがその友人(ドンさん)による記事。彼女の記事には「絵はイメージですシリーズ」というタグがついているのだが、このタグがついていない記事が4つほどあるらしい。せっかくなので、その4記事をプログラムで探してみることにした。(※ご本人の承諾を得た上で!)
戦略/概要
Doc2Vecというアルゴリズムを使って、すでに判明している本人が書いた記事と「似ている」記事を探しだす。
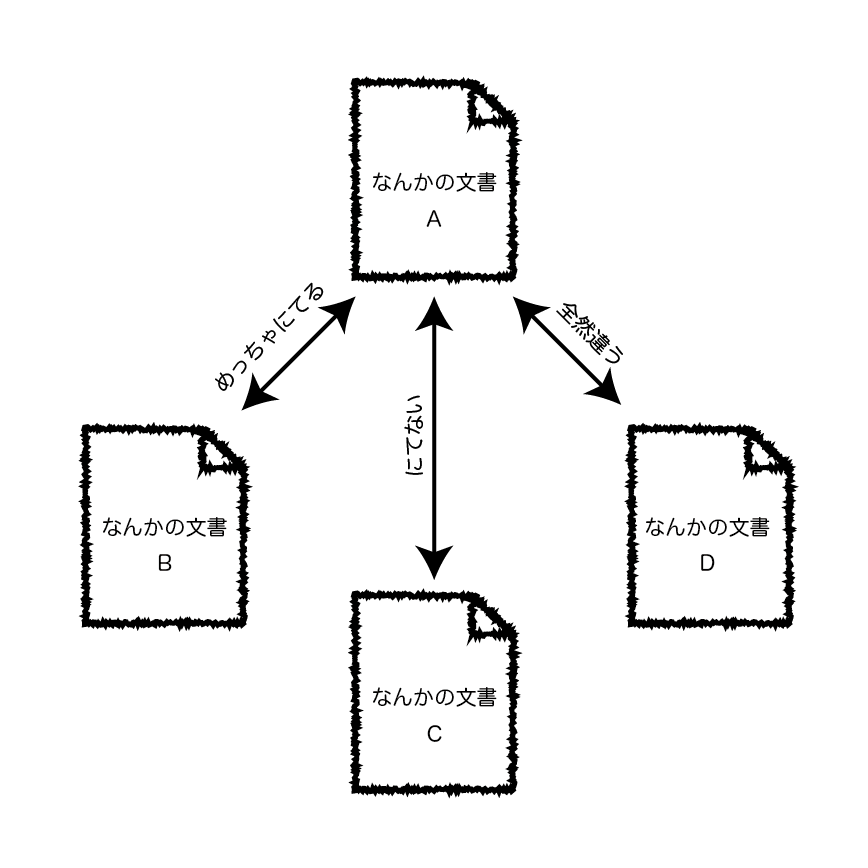
Doc2Vecというアルゴリズムをつかうと、文書間の類似度を計算することができる。この仕組みを使って、「ドンさんが過去に書いた記事」に近い記事を探しだせば、それがきっとドンさんの書いた記事だろう、という仮説・方針を立てる。
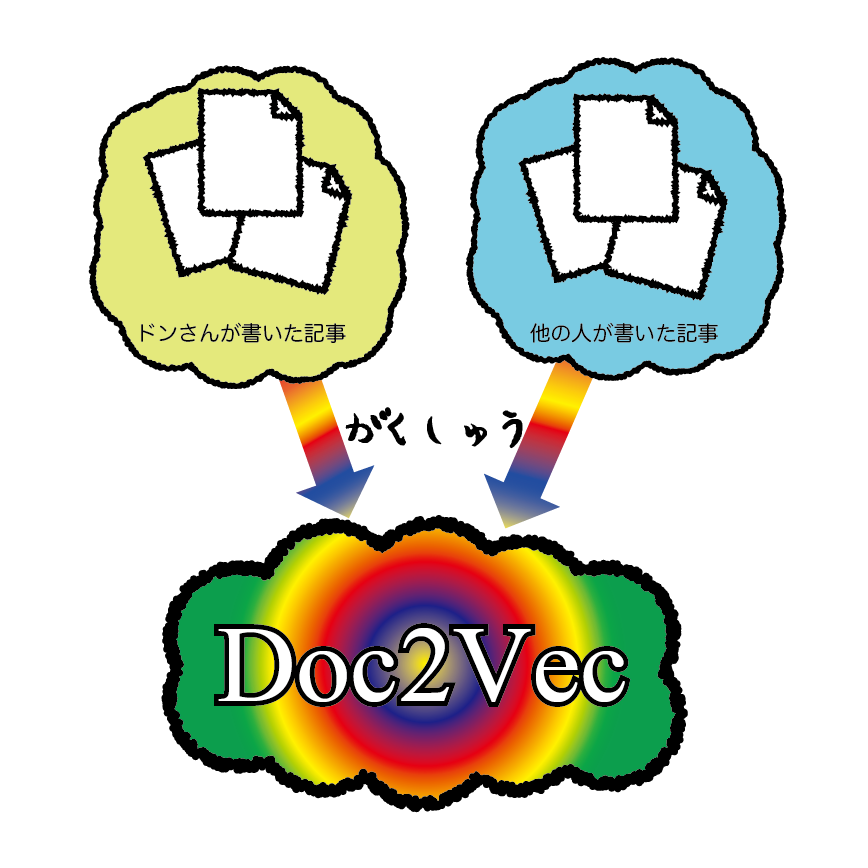
まず、あらかじめ「ドンさんが書いた記事」と「他の人が書いた記事」を学習させる。
次に、サイト上の未知の記事269件について、1件ずつ「本人が過去に書いた記事」との類似度を計算し、「似ている」記事を探す。

最後に、「似ている」と判定された記事が本人のものだったか、答え合わせをする。
すでに判明している記事が10記事で、1記事あたりの単語数が300前後、と極めて少ない学習データで、どこまで正しく予測できるか、が肝となる。
学習データの用意
「ドンさんが書いた記事」を学習させるためのデータを用意して学習させる。
ドンさんが書いた記事を10個と、他の人が書いた記事を26個を学習データとした。
「ドンさんが書いてない記事」を確実に知る術はなかったので、ドンさんご本人に「自分が書いていない記事」を教えてもらい、これを非正解学習データとした。正解学習データの件数と合わせて10記事にしようかと思ったのだが、あまりに学習データが少なくなってしまうので、アンバランスだがこちらは26記事を学習データにすることにした。
本来であれば、このデータを学習データと検証データに分け、学習がうまくいっているかの判断・チューニングに使用するべきなのだが、この分量でさらに学習用データが減ってしまうと明らかに学習がうまくいかなくなってしまう様子だったので、検証データに分離することは諦めた。
前処理: わかち書き、ステミング

Doc2Vecで学習しやすいように、各記事に前処理を行って、単語の配列に変換する。
まず、HTMLを解析し本文のみを抽出する。さらにMeCabで分かち書きを行い、原型単語のリストに変換する。
語形の変化がある単語は原型に直しておく。ストップワード(「です」「だ」などのあまり意味のない単語)の除外は今回は行わなかった。
学習
正解学習データ・不正解学習データ(の原型単語配列データ)それぞれ「正解」「不正解」のタグを付けてDoc2Vecに突っ込み学習をさせ、モデルを生成させる。この学習済みモデルを使って、未知の記事に対して推論を行なっていく。
検索対象データの用意
最新の記事から、上記学習データや「お知らせ」などを除いた269件を、検索対象データとした。ご本人にリストを見せて、この中に正解となる4記事が含まれていることを確認した。
この269件に含まれる正解4件を見つけ出すのを目標とする。
推論
学習済みのモデルを使って、検索対象の269件について「過去のドンさんの記事」との類似度算出を行い、スコアの高い順に10個の記事をリストアップした。
一応全部目を通してみたのだが、人間である自分の目(脳?)でみても、本人による記事か、そうでないか判断することが難しいものばかりだった。ただ、明らかに違うと思われるものは含まれていないようだったので、このリストを本人に渡して答え合わせをしてみた。
結果: 上位6記事のうちの4記事が正解だった
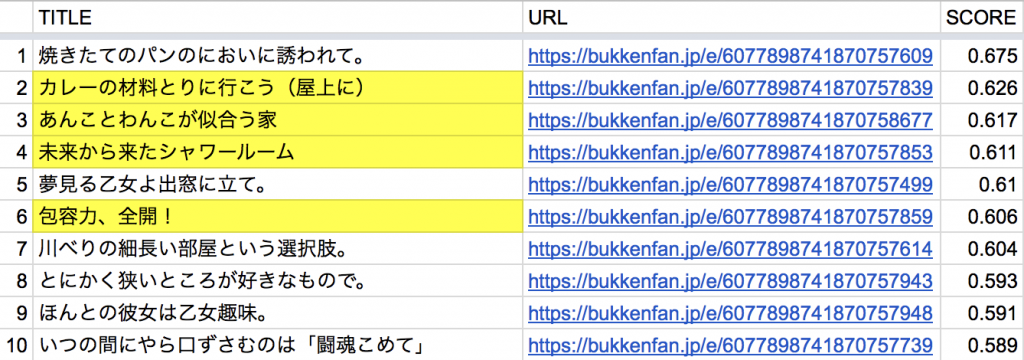
結果、2, 3, 4, 6位に正解が含まれていた。スコアが一番高い記事が不正解、というのはちょっと残念だが、限られた学習データの中では思っていたより大分良い結果が出たように思う。
考察
細かい試行錯誤は省略したが、如何せん学習データが少ない中で、どこまでできるかというチャレンジになった。学習データの件数が絶対的に少ないため、データを学習用データと検証用データに分離するわけにもいかず、今回の結果も偶然良い結果が出たのか、妥当な精度なのか判断するのが難しい。
今回の学習/推論においては、文書のコンテンツ(題材)より文体(言葉の選び方、語形の変化など)に特徴として使うべき情報(ニュアンス)が現れると考えられた。仮に、
- AさんがC(プール付きの別荘)について書いた記事
- BさんがC(プール付きの別荘)について書いた記事
- AさんがD(一人暮らし用のアパート)について書いた記事
- BさんがC(一人暮らし用のアパート)について書いた記事
という4記事があった場合に、コンテンツという点における類似度では1と2の記事の類似度が高くなり、文体という点における類似度では1と3の記事の類似度が高くはずで、そう考えるとステミング処理を行わない方が後者のスコアが高くなりそうだった。ただ、残念ながらおそらくデータ量の問題で、前述の通りステミングを行わないと学習がうまく進まない様子だったので、ステミングは行うことにした。
データが少ないことを言い訳にしてきたが、その後記事がある程度増えてきているようなので、後でデータ量を増やして再検証を行おうと思う。
さて、最近の彼女の記事は突然漫画になった。
漫画になったことでより彼女の独特の世界観が表現されているので、是非読んでほしいところ。
「機械学習(Doc2Vec)で、友人の投稿を見つけ出してみた」への1件のフィードバック