経緯や詳細は下記の記事に書いたのだが、けものフレンズというアニメに出てくるボス(ラッキービースト)というロボットみたいな何かをiPhoneで作ってみた。
至極簡易的ではあるものの、はじめてロボット/AI的なものを自分で作ってみて色々と技術的にも学んだことが多かったので、ここに書き記しておこうと思う。
今回のシステムの全体像
アニメに出てくるラッキービーストは、いわゆる汎用人工知能(強いAI)なのだが、さすがにそれを実現するのは難しいので、今回は「モノを見せると、それについて教えてくれる」人工無脳的な実装をすることにした。
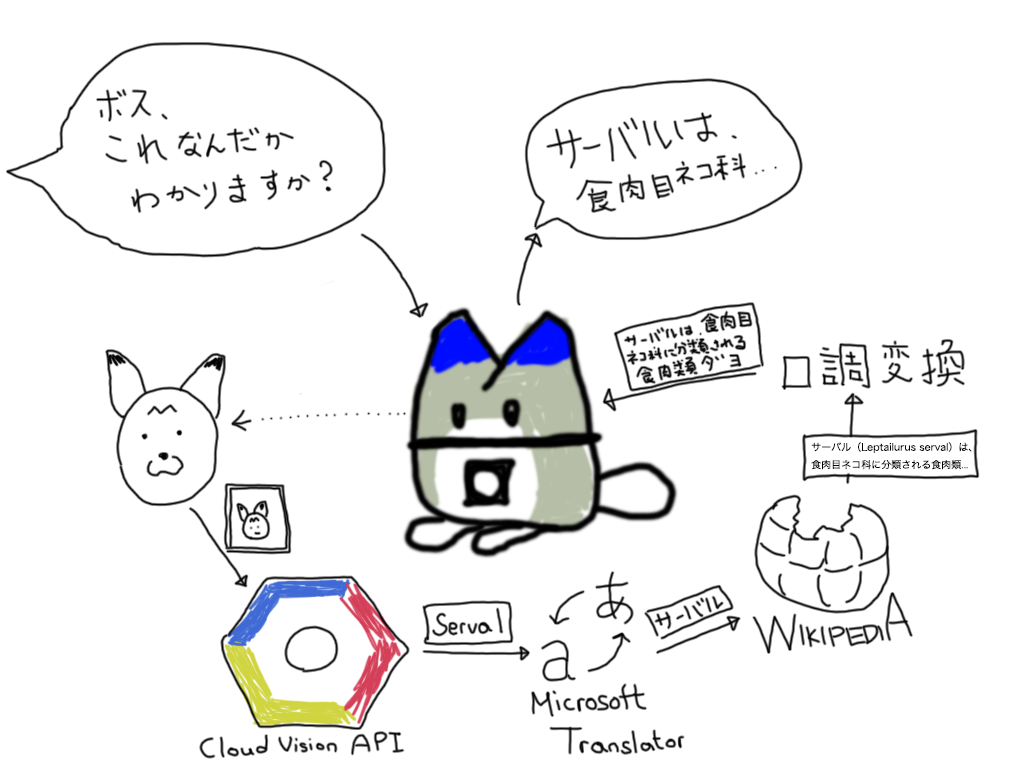
大まかなシステムの流れはこんな感じ。
- 音声認識で「これなんだかわかりますか?」的な質問をされたことを検知する
- カメラを使って、目の前の様子を撮影する
- 撮影した画像から物体を検出する
- 検出した物体について、Wikipediaで情報を調べる
- 適当に文章にして音声合成で喋る
一昔前であれば、これら一式を自前で用意する必要があったかもしれないが、後述の通り2017年現在では、既製のライブラリ/AIを組み合わせるだけで十分それっぽいものが出来上がった。
iPhoneか、Raspberry Piか
最終的には、手足や耳を動かしたいと考えており、その点ではRaspberry Piをベースに開発したほうが良さそうだったのだが、下記の理由で最初のプロトタイプはiPhoneをベースに作ることにした。
- 音声認識や音声合成の認識が容易に実装できる
- ハードウェアの購入・設定の手間がない
- 色々な人のiPhoneにインストールして試してみてもらうことができる
実際のところ、今回のプロトタイプはiPhoneをベースにしたことで大分サクサク実装が進んだ。
音声認識 – iOSのSFSpeechRecognizer
ちょうどiOS 10からSFSpeechRecognizerという音声認識APIが提供されていたため、これを使った。運良く日本語にも対応しており、精度/レスポンス共に良好だった。
SFSpeechRecognizerを使うと、マイクからの入力を文字列で取得することができる。今回のプロトタイプでは、単純なパターンマッチングで「○○ってなんですか?」のようなパターンが出てきた場合に、撮影〜検索のフローが動く仕組みにした。(細かい話になるが、「これ」を含む場合はフロントカメラに写っている物体について、「これ」が含まれない場合はその単語を直接調べるような実装になっている)
カメラに写る物体の検出 – Google Cloud Vision API
Google Cloud Vision APIのLabel Detectionの機能を使って、カメラに映った画像から物体の検出を行なっている。TensorFlow + Googleが公開している物体検出用の学習済みデータセットを使って、iPhone上でリアルタイムに物体検出を行う方法も検討したが、組み込みやすさという点では、Google Cloud Vision APIを使う方が圧倒的に簡単だったので、そちらを優先した。
Label Detectionの機能を使うと、画像内に写っている複数の物体の「ラベル」が「確かさ」付きで検出される。(「車」が写っている確率は95%、「メガネ」が写っている確率は5%、など…)。物体は複数返されるので、「どの物体について説明させるか」というのがとても重要になるのだが、現在は「一番認識の確度が高い物体」を選ぶようにしている。本来であれば、画面の中央部に近いか、画面に占める面積が多いか、前後のフレームと比べて動きがあるかどうか…などの基準で考えるべきなのだが、現段階ではそこまで実装できていない。
Google Cloud Vision APIは、導入が楽で最初のプロトタイプ用に使うにはとても良いのだが、実際に今後使い倒していこうとするといくつか問題がありそうだ。
まず、結果が英語で返ってくること。ラッキービーストには日本語で喋らせたいので、どうしても英語から日本語への翻訳が必要になってしまう。当然ながら、英単語とそれに対応する日本語のパターンは一種類ではないし、文脈のない状態での翻訳は情報量を失わせる結果になってしまう。こんなところで言語の壁を感じることになったが、おそらく日本中(あるいは英語圏以外の他の国々)で似たような悩みが発生しているのかと思うと、日本語に最適化された学習済みデータセットを作れれば結構価値があるのかもしれない。
次に学習データの問題。Google Cloud Vision APIで検出できるラベルは、汎用的に使えるワードがメインだ。ラッキービーストの場合、アニメの設定に忠実に作っていこうとすると、「動物の種類を正しく検出できるか」というのが重要になりそうなので、汎用的なワードを扱うGoogle Cloud Vision APIデータセットでは精度を出しにくそうだ。都合よく動物の識別に最適化されたデータセットがあったとしても、現状ではGoogle Cloud Vision APIでデータセットを切り替える方法は用意されていないので、使うことができない。
この部分の精度を上げて最適化をしていくには、最終的にはTensorFlow+自前で用意した最適化された学習済みデータで実装をする必要がありそうだが、それはなかなかハードルが高そう。
検出結果の翻訳 – Microsoft Translator API
Google Cloud Vision APIで検出されたラベルは英語表記なので、これを日本語に変換してやる必要がある。GoogleのTranslate APIを使ってもよかったのだが、無料枠がないのでMicrosoft Translator APIを使うことにした。GoogleのTranslate APIも有料とはいえ極めて安価なのだが、どうも最初の一リクエスト目から有料と言われて心理的にハードルが上がってしまった…。
Microsoft Translator APIは、API自体のパフォーマンスと精度自体は悪くないし、何より一定量まで無料で使えることは非常にありがたいのだが、レスポンスがXMLだったり、設定画面が多少分かりにくかったりと微妙に使いにくい部分があってそこそこ苦戦した。クラウド死は怖いけれども、トータルでみるとGoogle Translate APIの方が何かと良さそうな気はしている。
Wikipediaのサマリーから、ボスっぽい文体の説明文を作る
検出した物体について、Wikipediaを調べてそこに載っている情報から、ボスっぽい文体の説明文を生成する。
実は今回のプロトタイプは、「Wikipediaに載っているサマリーをボスっぽい文体に変換する」というところから実験を始めた。この手の実験は、iPhoneアプリとして実験するより、スクリプトで実験した方が早いので、Rubyを使って実験していた。
元々は、ここで実験した内容を元にSwiftで実装し直すつもりだったのだが、面倒くさくなってしまったので、結局ここはRubyのスクリプトのままHerokuにデプロイして、APIとして使えるようにした。
Wikipediaからサマリーの抽出 – wikipedia client gem
Rubyのwikipedia clientというgemを使うとWikipediaのサマリーの取得が非常に容易にできるため、このgemを使ってWikipediaからサマリーを取得する。
サマリーからボスっぽい文体の説明文への変換
取得したサマリーを、本来であれば自然言語処理をして文体を変更させるべきところなのだが、例によって面倒くさかったので単純なルールで置換してみたら、意外とそれっぽくなったので、それでよしとした。
- 括弧でくくられた注釈や補足説明を取り除く
- 文章を読点(。)で区切る
- ボスっぽい語尾(「〜らしいよ」「〜だよ」)に置き換える。語尾はランダムに選ぶ。
これだけなのだが、意外とそれっぽい結果が得られる。もちろん、語尾置き換えのルールが完全ではないので、たまに変な文章が出来上がったりするのだが、最初のプロトタイプなので気にしない。
音声合成 – iOSのAVSpeechSynthesizer
最後に、生成した説明文をiOS標準のAVSpeechSynthesizerで喋らせる。残念ながら、iOSで使える日本語の文字列読み上げの音声は一種類しか用意されておらず、声の高さや速度は調整できるものの、エフェクトをかけたりすることができないため、満足できるほど声質を調整することはできなかったが、なんとなくそれっぽい感じにはなった。
イコライザーをかけることができれば、もう少しボスっぽい感じにできそうなのだが、少なくともiOS 10ではそのようなことができない。ここの声は何気に大事なところなので、将来どうするか検討していきたい。
そこそこ漢字の読み間違えやイントネーションがおかしい箇所があるのが気になるが、まあこれもボスの愛嬌で相殺されるので問題はない。
ちなみに、なぜかiPhoneとiPadでは微妙に読み上げ時のイントネーションが変わるようで、非常に不思議。
まとめ
とにかく早く動くものを作りたくて勢いで作ってしまったので、いろいろなところでクオリティが犠牲になっているが、上述の通り既製のAPIやライブラリの組み合わせだけで、それっぽく動くものを作ることができた。しかも、発泡スチロールと塗料以外お金はかからなかった。素晴らしい時代にエンジニアになれたことを感謝したい。
音声認識のSFSpeechRecognizer、音声合成のAVSpeechSynthesizer、物体認識(ラベリング)のGoogle Cloud Vision API、翻訳のMicrosoft Translator API、これら全て、内部的には高度な機械学習の技術が使われているはずだが、ほとんど機械学習に触れたことがない自分でも、簡単に使える形でその技術の恩恵を受けることができるというのは本当に素晴らしい。機械学習はハードルが高そうだと感じている人は、是非触れてみてほしい。
今後、よりアニメに出てくるラッキービーストのように愛嬌のあるロボットにしていくには、これらのAPI/ライブラリを組み合わせて使っているだけでは限界があるのは間違いないと思う。一方で、これらの各機能、あるいは中心となる汎用人工知能としてのシステムを個人で開発していくのも、多分現実的ではない。当面はこれらのライブラリを使いながら、調整・最適化を続けて、より楽しいものにしていければいいなと思う。その間に、何かしらライブラリ/API側も進化したり新しいものが出ることを期待したい。
いつかは、ボスの前に物体を見せて「これは○○だよ」って喋りかけると学習してくれるような、そんな仕組みだったり、ハードウェア的にも歩いたり耳を動かしたりできるようになったらいいなと考えながら、ゆっくり開発していこうと思う。
なお、ソースコードを公開してあるので、興味がある方はどうぞ
yokoe/luckybeast-ios