ふと、日曜日の夜に「写真をアップロードしたら、なんのフレンズか判定してくれる」システムを作ったら面白いのではないか、と思い立った。ちょうど金曜日にコミケが開催されるというので、友人に手伝ってもらいつつ勉強を兼ねてなんとか5日間でシステムを作ってみた。その記録。
1日目
突然、写真をアップロードしたら「なんのフレンズか」を答えてくれるサービスがあったら面白いかなと思いついて、開発をはじめた。友人らに手伝ってもらい、ウェブ上にアップロードされているけものフレンズのコスプレ画像を手動で集め、顔の周辺をクロップした画像を用意していく。集めたのは「カバン、サーバル、アライさん、フェネック、カワウソ、トキ、ハシビロコウ」の7種類。各フレンズごとに、本当は数百枚程度、欲を言えば数千枚程度画像が欲しかったのだが、なかなか画像が見つからず、結局各50枚前後しか集められなかった。
枚数は明らかに足りないのだが、とりあえずTensorFlow/Kerasで簡単なCNNの分類器を作り、学習をさせてみた。入力は64px * 64px * 3チャンネル(RGB)。学習データの少なさを補うため、KerasのImageDataGeneratorの機能を使って、ZoomやHorizontal Frip、Rotationなどのデータオーギュメンテーションを実施したが、やはりすぐに過剰適合が起こってしまう。データが少ないので全然当てにならないのだが、検証データ(未学習データ)を使ったAccuracyは80%前後。

2日目
あまり深く考えず、出力層にはSoftmaxを使っていたが、Softmaxを使うとどのような画像を与えたとしても、必ず各カテゴリのスコアの合計が1になってしまう。全然関係のない画像をアップロードしたとしても、「辛うじていうなら、サーバルである確率が95%」みたいな結果になってしまうのは不適切だということに気がついた。
そこで、出力層の活性関数をSigmoidに変更することにした。こうすることで、どのフレンズの特徴にもあわない画像を「どのフレンズともマッチしない」と判断できるようになるはず。Sigmoidを使った場合でも、Softmaxを使った場合でも「最も可能性が高いもの」は同じ結果になるべき(スコアは変わるが)なので、Sigmoidに変えることによる問題はなさそうだ。(学習の効率とかは影響あるかもしれないけれども)
モデルを変更して学習させ直して実験。試しに40枚ほどの未学習のテスト画像を分類させてみたところ、10枚については正しく分類できたのだが、残りの30枚については「どのフレンズともマッチしない(スコアが50%以上のものがない)」となってしまった。
精度を上げるために、顔周辺の領域のみを切り出して学習・評価させるようにしようと思っていたのだが、コスプレをしていると通常の顔検出がなかなかうまく動かないようだ。OpenCVを使った場合も、Google Cloud Vision APIのFACE_DETECTIONを使った場合も、残念ながらそこまで精度が出なかった。顔周辺部分を切り出しての学習・評価については一旦保留する。R-CNNで使われているようなSelective Searchを使った切り出しを検討することにした。
いずれにせよ、学習データを増やしてもっと精度を向上させる必要があることだけは間違い無いのだが、画像を集める目処が立っていない。いっそ、コスプレ画像を学習させる形ではなく、アニメの方を学習させて、コスプレ画像を評価させる形にしようか悩む。
Webサービス化のための実装方法についても、そろそろ勉強しなければ。Webサービス化するにあたって、Herokuでホスティングするか久しぶりにVPSを立てるかも、迷っている。
友人が昨日に引き続き献身的に学習データを集めてくれていてありがたい限りなのだが、「サーバル」のデータの中にジャガーさんが何人か混じっているようだ。この辺りは訓練された人間でないと誤差が大きくなってしまうようだ。
久しぶりにニコニコ動画で1話を見たが、もうすぐ1000万再生なのか。すごーい。
3日目
画像のサイズを128px * 128pxに拡張してみたのだが、精度は上がらなかった。VGG16ベースでFine Tuningをするようにしたら、数字上85%程度までAccuracyが向上したのだが、実際に分類させてみると、数字以上に精度が上がっている感じがする。
昨日試した40枚を同様に分類させてみたところ、見事に全て分類に成功した。「どのフレンズともマッチしない(スコアが50%以上のものがない)」も0枚だった。

しかし、Fine Tuningを試していると、一定の割合で学習を失敗してしまう。やはり学習データが圧倒的に少ないせいなのかもしれないが、困った。
4日目
横浜にピカチュウ大量発生チュウを見に行ってきた。

毎年見に行っているのだが、可愛い。今年はメタモンには会うことができなかったが、ミミッキュに会うことができた。
Flaskを使ってWebサービス化する準備を始めた。HerokuかGoogle App Engineを使ってホスティングしたかったのだが、両方とも若干設定に手間がかかりそうだったので、まずはVPS上で動かす形にして、後で検討することにした。
今回の判定器は、学習データが限られていることと、物体検出の実装の簡易化のために、顔周辺部の画素のみを学習させるようにしている。推論の方でも、アップロードされた画像の中から顔周辺部の画素を使って評価をするようにしたい。
そこで、顔検出についてOpenCVを使った場合とGoogle Cloud Vision APIを使った場合を比較してみた。(1枚の画像で2個の誤検知があった場合は、誤検知数は2とカウント)
| Library/API | 検出成功数(枚) | 誤検知数(個) |
|---|---|---|
| Cloud Vision API | 53 / 71 | 0 |
| OpenCV(default) | 36 / 71 | 85 |
| OpenCV(alt) | 24 / 71 | 2 |
結果は上記の通りで、圧倒的にGoogle Cloud Vision APIによる顔検出の成績が良い。今まであまり顔検出を使うようなプログラムを書いたことがないので、比較できないのだが、コスプレをしているせいか期待していたよりいずれのライブラリ/APIも検出の精度が低い。
OpenCVの方が実装が容易だし、お金もかからないのだが、Google Cloud Vision APIのFace Detectionの方が圧倒的に精度が高く、またこの部分の精度はシステム全体の精度に与える影響が大きいので、Google Cloud Vision APIを使って顔の検出を行うことにして実装した。これで、学習データが不十分な割に、なんとかそれっぽく動くようになってきた。もちろん、学習データに対する過剰適合が起きているのは間違い無いのだけど…。
5日目
コスプレ画像を頑張ってもう少し集めて、学習データの増強に務める。まだまだ精度に納得感はないのだけど、一旦モデルの学習はここら辺で区切りをつけて、後でぼちぼち改善していこうと思う。
あとはひたすらアップロード用のウェブインターフェイスの開発を進める。Flask + Hamlish + Bootstrapでインターフェイスを作ることにした。Hamlishは最初は違和感があったが、HTMLからコピペがしやすいというメリットがあることが理解できた。Flaskは、テンプレートを更新した際に自動的に内容が反映されないのが煩わしい。自動的に反映させる方法があるのかもしれないが、結局わからなかった。
サーバーについては、@hm0429のサーバーに設置させてもらうことにした。デプロイもスクリプト化してもらって、良い感じ。余裕ができたら、勉強を兼ねてGAEに移動してみる予定。
6日目
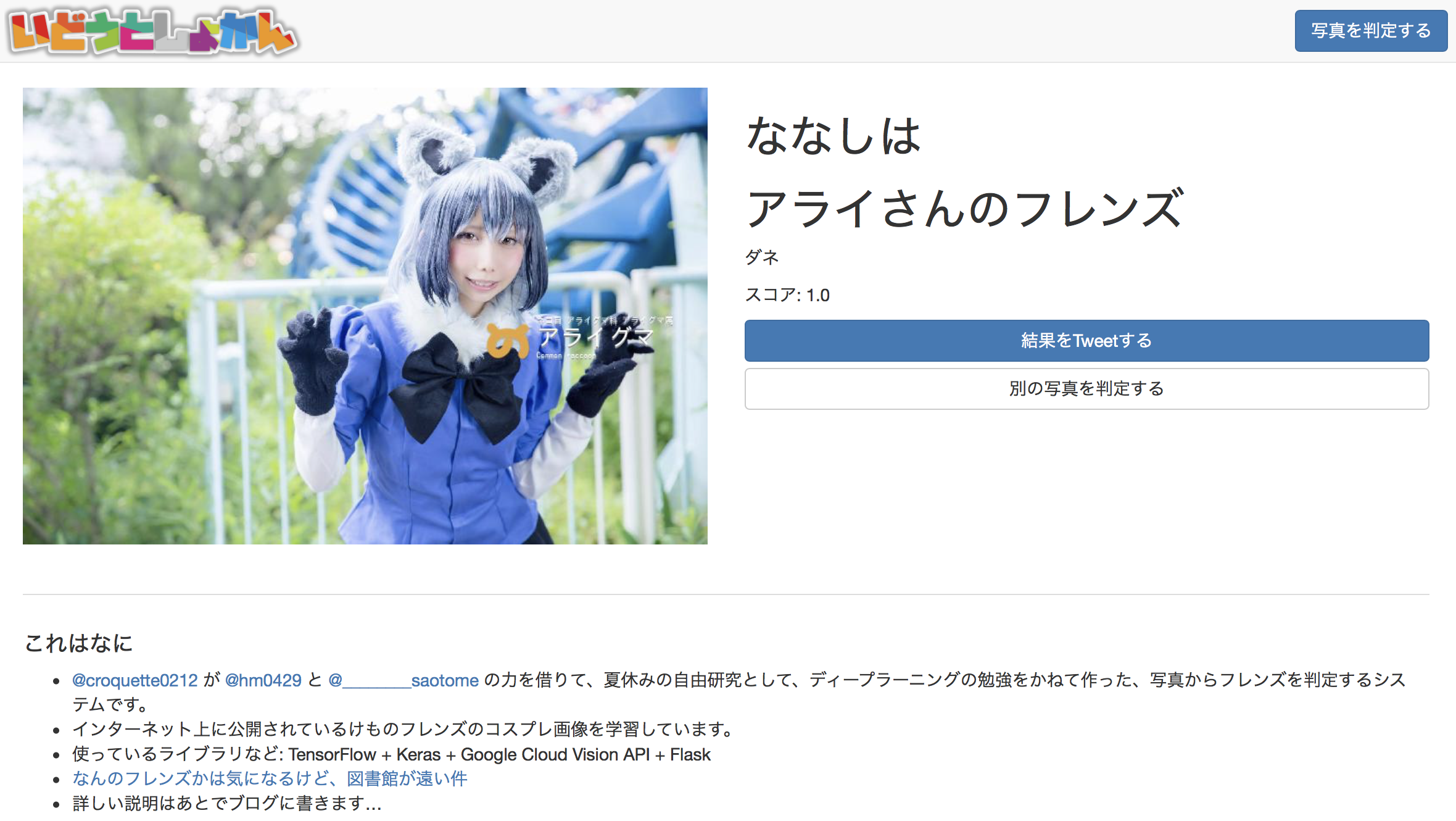
最後に無理矢理最低限見た目を整えて、なんとかリリース!
早速試してくれている人もぼちぼちいて、嬉しい限り。
公開後の日記(追記)
精度
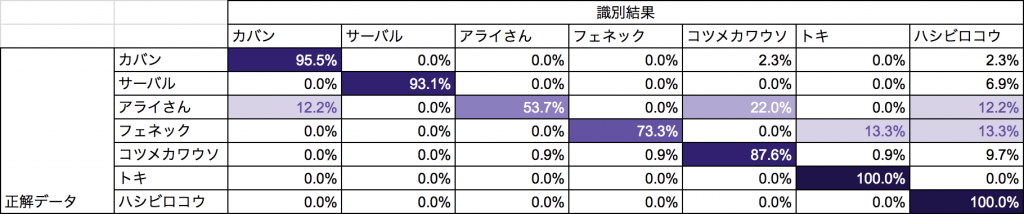
Twitter上にアップロードされていた、コミケ期間中のけものフレンズのコスプレ画像294枚(未学習)を使って、識別をしてみた。突貫工事で、少ない学習データで作った割にはなかなかの精度が出ている気がする。アライさんを間違えてコツメカワウソと判定してしまう率が若干高いようだ。
利用デバイス
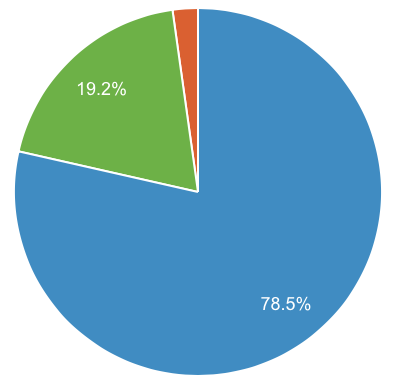
主にTwitter経由で拡散されたこと、またコミケ期間中に見てくださった方は基本的に外出中だったことなど、色々理由は考えられるが、モバイルの利用率が想像以上に大分高い。リリースから10日間で見ると、実に78.5%がモバイル(タブレットを含まない)での利用となっている。
やはり、本格的に今後何かWebサービスを作るときも、スマホファーストで考えなければいけない時代なのだなあ。
「フレンズ判定器を作った時の記録(1日目〜6日目と公開後の追記)」への1件のフィードバック